Benchmark Comparison
How does VANTAGE-Bench fit into the existing evaluation landscape?
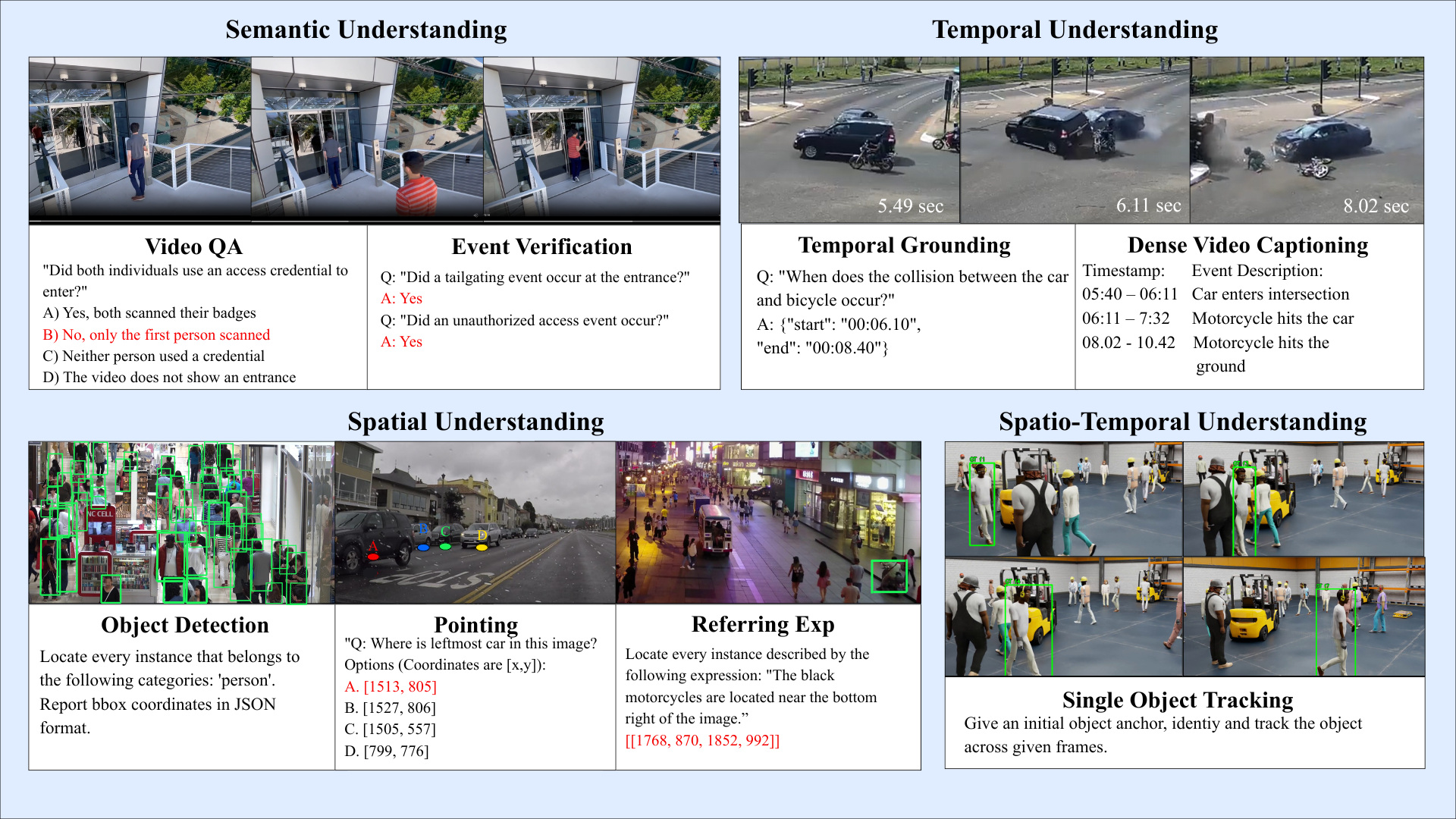
Most VLM benchmarks focus on a single reasoning dimension and typically cover only one modality. VANTAGE-Bench is the first benchmark to jointly evaluate all four reasoning dimensions across both image and video in a single suite.
Table 1 — Scope comparison
What this shows: how VANTAGE-Bench compares to the benchmarks it most directly relates to in terms of scale, modality coverage, and task diversity.
| Benchmark | Modality | # Media | # Annot. | Reasoning coverage | Annotation source |
|---|
| VideoMME | Video | 900 | 2,700 | Semantic only | Human |
| BLINK | Image | 3,683 | 1,906 | Spatial only | Human, Existing |
| RefCOCO avg. | Image | 3,982 | 30,969 | Spatial only | Human, Existing |
| ODinW-13 | Image | 4,608 | 10,966 | Spatial only | Human, Existing |
| Charades-STA | Video | 1,334 | 3,720 | Temporal only | Human, PL |
| ActivityNet Cap. | Video | 5,044 | 17,750 | Temporal only | Human |
| VANTAGE-Bench | Image + Video | 3,346 | 35,027 | All four pillars | Human + Synthetic + PL |
PL = programmatically generated labels from human-verified annotations
Table 1: VANTAGE-Bench is the only benchmark spanning all four reasoning dimensions across both image and video modalities.
Does VANTAGE-Bench actually measure something different?
Yes, and by a significant margin. The table below compares the same model (Qwen3-VL-8B) on published scores on standard consumer-centric benchmarks against its scores on equivalent tasks in VANTAGE-Bench.
Table 2 — The performance gap
Qwen3-VL-8B zero-shot scores on the standard reference benchmark for each task vs. its score on the equivalent VANTAGE-Bench task. A negative gap means the model performs worse on VANTAGE-Bench. All scores are scaled 0–100.
| Task | Reference benchmark | Ref. score | VANTAGE score | Gap (∆) |
|---|
| Semantic Understanding |
| VQA | VideoMME | 71.40 | 65.47 | -5.93 |
| Event Verification | MLVU | 78.10 | 48.14 | -29.96 |
| Spatial Understanding |
| 2D Pointing | BLINK | 69.10 | 45.54 | -23.56 |
| Referring Expressions | RefCOCO | 89.10 | 71.55 | -17.55 |
| Object Localization | ODinW-13 | 44.70 | 37.72 | -6.98 |
| Temporal Understanding |
| Temporal Localization | Charades-STA | 56.00 | 41.35 | -14.65 |
| Spatio-Temporal Understanding |
| Single Object Tracking | No prior benchmark exists | n/a | 31.44 | n/a |
Table 2: Performance gap for Qwen3-VL-8B across tasks. Negative values indicate degradation on VANTAGE-Bench relative to the standard reference benchmark for that task. The largest drops occur in Event Verification (−29.96) and 2D Pointing (−23.56), confirming that fixed-camera footage breaks priors that models rely on in consumer-centric settings. Single Object Tracking has no reference score because no prior VLM tracking benchmark exists. * Qwen3-VL-8B scored 31.44 AUC on SOT; best overall is Gemini 3.1 Pro at 64.35 AUC.